Recherche de moteurs Recherche de moteurs
 Curieusement,
alors qu'il suffit de valider n'importe quelle requête dans un moteur de
recherche pour avoir au minimum des centaines de résultats, en
écrivant "moteurs de recherche" on obtient aussi une liste, mais peu
d'informations sur les outils eux même. Alors, comme j'avais très
moyennement envie de bosser aujourd'hui, je me suis perdu volontairement dans
les méandres du Net pour comprendre comment fonctionne Google et savoir si
quelques concurrents ont survécu à son expansion fulgurante. Curieusement,
alors qu'il suffit de valider n'importe quelle requête dans un moteur de
recherche pour avoir au minimum des centaines de résultats, en
écrivant "moteurs de recherche" on obtient aussi une liste, mais peu
d'informations sur les outils eux même. Alors, comme j'avais très
moyennement envie de bosser aujourd'hui, je me suis perdu volontairement dans
les méandres du Net pour comprendre comment fonctionne Google et savoir si
quelques concurrents ont survécu à son expansion fulgurante.
En 1993, au néolithique du
WWW, le premier moteur de recherche digne de ce nom, indexant des pages
entières, s'appelait WebCrawler et fut conçu par
Brian
Pinkerton, alors
étudiant de l'Université de Washington, qui en réalisa, en
premier, un desktop programm en interne avant de développer l'application
en ligne avec un remarquable succès quasi immédiat. D'ailleurs, les
algorithmes de base, bien qu'améliorés, sont toujours implantés
en 2005 dans les moteurs de Yahoo, HoBot et ICQ. Bien peu des "search engines"
des premières années du Web ont survécu à l'euphorie
financière de cette période. Pour en citer quelques-uns, qui se
souvient d'Infoseek, Excite ou plus proche de nous, Lycos
?Cette première
génération d'outils traquait l'information demandée avec l'aide
de "spiders" (araignées) parcourant les pages, les noeuds et les liens de
la toile suivant ce principe
:- un logiciel permet de
parcourir le ou les
réseaux- une base de
données correspondant aux résultats collectionnés par le
robot- un moteur de recherche
grâce auquel l'utilisateur arrive à trouver les éléments de
la base de
donnéesGoogle
repose sur une méthode similaire en y ajoutant un système de
classement appelé PageRank. Le spider GoogleBot ramène ainsi sur les
serveurs Linux de traitement de Google une masse colossale d'informations qui va
être analysée dans les moindres détails. À chaque mot ou
phrase est en effet associé son type, basé sur le langage HTML. C'est
ainsi qu'un mot contenu dans le titre sera jugé plus important que dans le
corps du texte. Une échelle de valeurs répertorie les types de mots
(titre de la page, titre de paragraphe H1 à H6, gras, italique, etc.). Plus
la page est visitée plus elle figurera en bonne position dans la
hiérarchie de référencement. C'est un procédé basé
sur la popularité du classement non pas sur la
pertinence.
Par exemple, votre site ne sera identifié par le Googlebot que s’il
est cité par des pages déjà bien établies. On est dans une
logique de réseau dans le réseau au détriment de la qualité
du contenu, qui devient accessoire. En grossissant un peu si vous écrivez
sur un sujet, et que le propos est relayé par beaucoup d'autres sites,
votre classement PageRank s'en trouvera amélioré. Que vos textes
soient du niveau CM2 ou d'une haute teneur littéraire, cela n'aura aucune
incidence. Autre constant,
mais qui ne concerne pas que Google: de nombreuses pages ne sont pas
identifiables sur le Net. Soit parce que certains sites officiels limitent
volontairement l'accès pour filtrer les demandes jugées sensibles
concernant des secteurs stratégiques :armées, organisations
gouvernementales et laboratoires expérimentaux. Soit dans un but lucratif
avec l'obligation payante de s'enregistrer pour avoir accès aux databases
désirées : bibliothèques, universités et réseaux
intranet de certaines grandes sociétés
commerciales.De toute
façon, la progression quasi journalière du nombre de pages crées
ne permet pas l'indexation en temps réel de celles-ci (tout au moins avec
les outils actuels).On
pourrait avoir la tentation de reprocher à
Google
ce qui fait l'essence même de sa popularité : être devenu
omniprésent et indispensable. Régulièrement des articles de mise
en garde du monopole googlien sont publiés ici ou là. Aussi pertinents
soient-ils parfois on peut cependant mettre en cause leur intention
sous-jacente. Google, au même titre que Micro$oft fait peur par sa
puissance et alimente en réaction des interrogations parfois
légitimes, mais souvent paranoïaques genre la collusion entre Google
et le gouvernement US, sa base de données soi-disant partagée avec des
cellules de recherche d'infos de la C.I.A., etc etc. Tout ceci étant
largement invérifiable pour l'internaute de base ! On envisage, on suppute,
on murmure que... pour le plus grand bénéfice, paradoxalement, du
moteur incriminé ! L'instrumentalisation des médias via la rumeur
orchestrée est un grand classique de tout gouvernement voulant garder le
contrôle et surveiller le flot d'infos en continu du
Web.J'ai testé
pour vous les principaux moteurs grand public les plus utilisés et je n'ai
pas, à une ou deux exceptions près, constaté de réelle
différence en terme de rapidité ou de pertinence. À savoir,
certains moteurs sont plus ou moins spécialisés dans des domaines
établis et j'ai volontairement exclu les metamoteurs de recherche qui ne
vous apporteront rien de plus pour trouver les URLs basiques disponibles à
99 % grâce aux moteurs
standards.Mon choix de taper
letitblog.org dans les différents appareils testés n'est pas du tout
le fruit d'un quelconque orgueil personnel, mais plutôt une astuce de
procédure : mon blog étant volontairement non répertorié ou
affilié à un ring car j'ai expurgé le code source de tout
metatag visible permettant aux spiderbots de "voir" la structure de mes pages
(niveaux 1 et 2). Je ne souhaite pas apparaître dans des annuaires ou des
listes qui me sont inconnues afin de rester dans le "Dark Web" selon la formule
consacrée. Donc en écrivant l'adresse letitblog.org ce fut un
excellent moyen de me rendre compte du nombre d'informations disponibles au
sujet de mon blog !Bon
visiblement, il doit rester quelque part une obscure portion de code qui
moucharde mon existence, mais je m'en vais de ce pas chercher et killer
l'instruction-indic...Siouplé
vous ne connaîtriez pas un bon Code cleaner pour que je puisse rester
underground ? Les voies du Web sont décidément bien
pénétrables.Quelques
pastiches rigolos ici,
ou là,
et une version de Google écrite en Klington,
qui comme chacun le sait est la langue de Star Treck
!les principaux moteurs
de recherche grand public (hors Google et en langue anglaise)
:All the
web
Altavista
AOL
Ask
Jeeves
Hotbot
MSN
search
Positiontech
WebCrawler
Yahoo
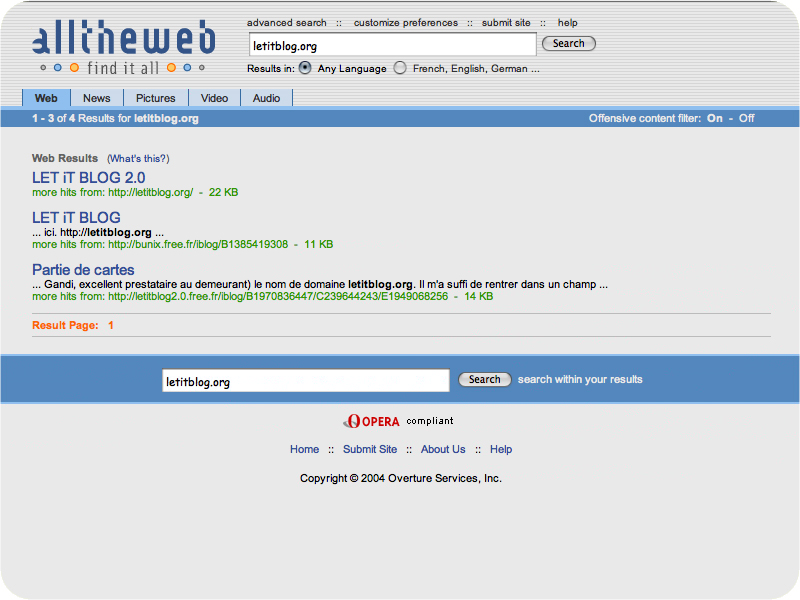
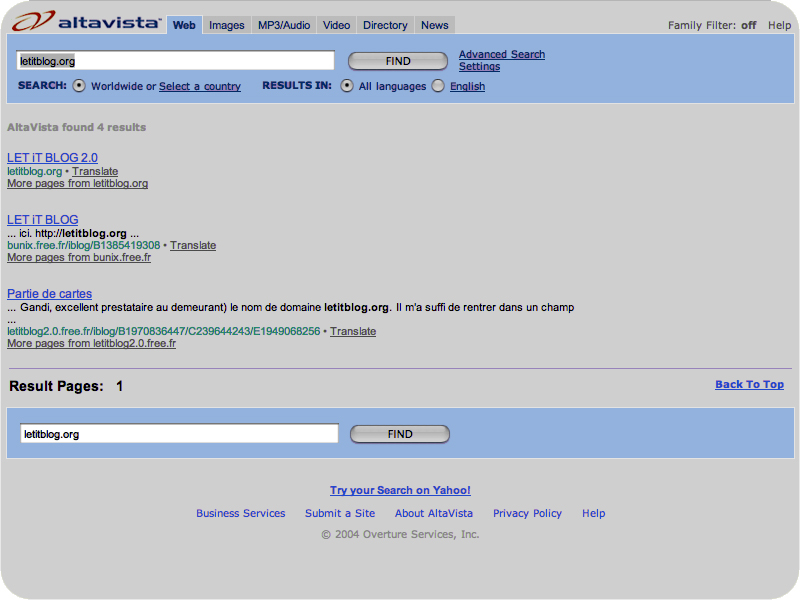
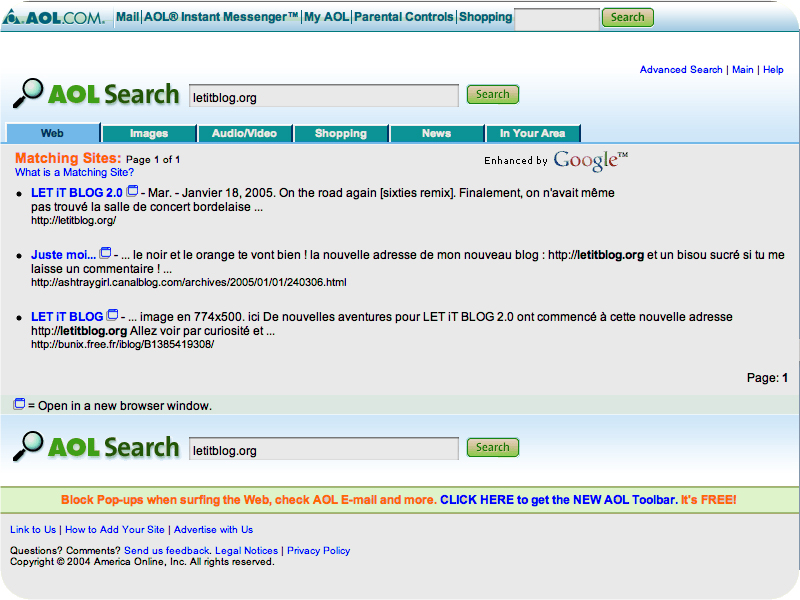
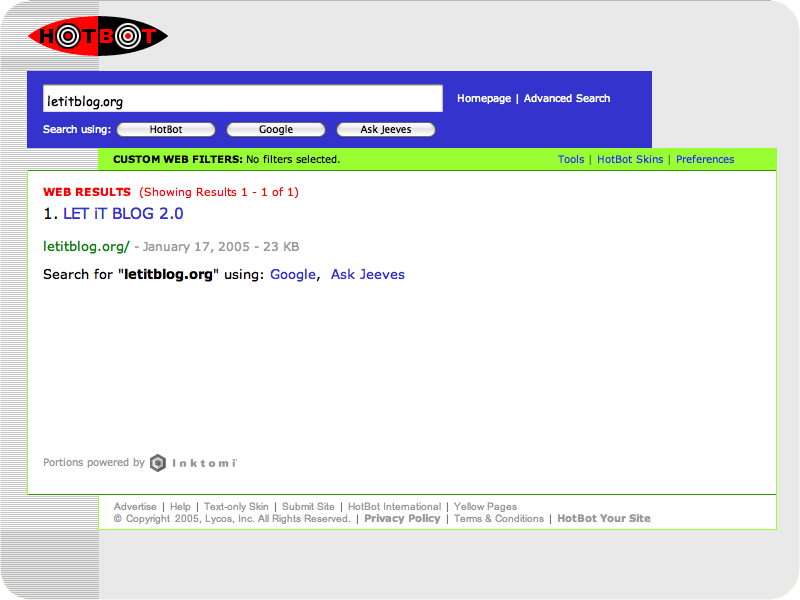
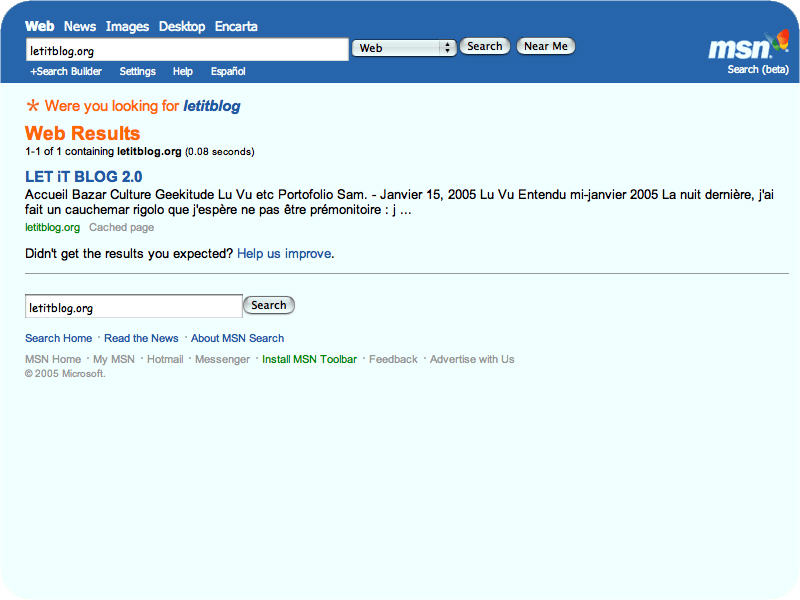
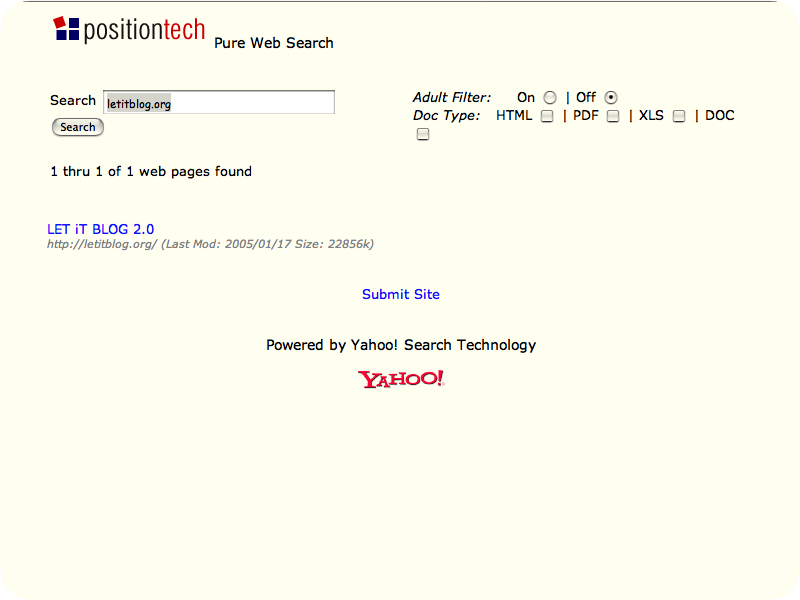
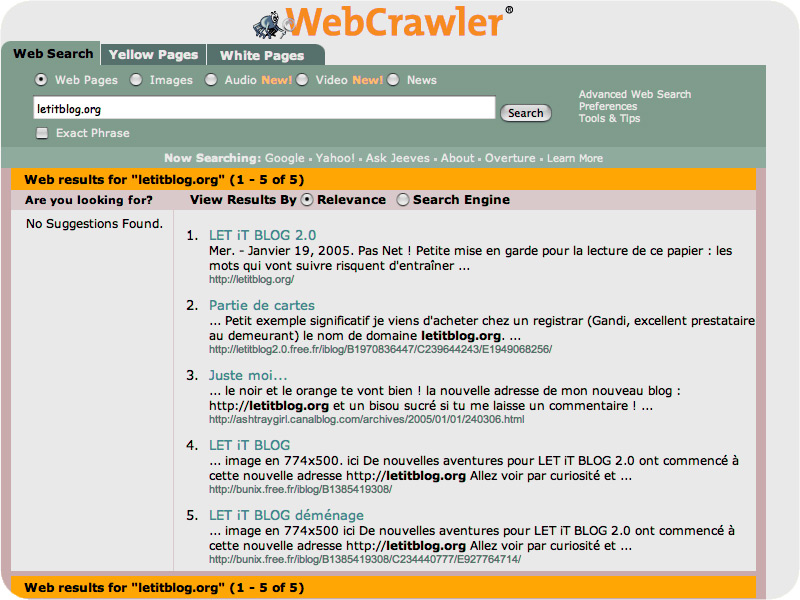
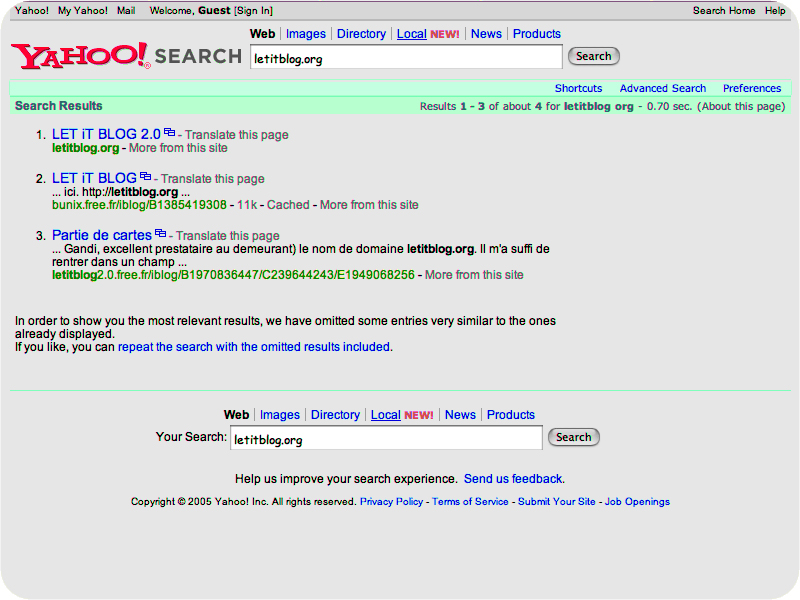
les résultats
obtenus avec ces moteurs pour la requête "letitblog" (screenshots)
: 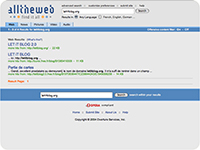 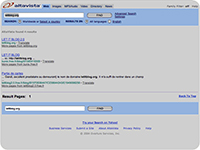 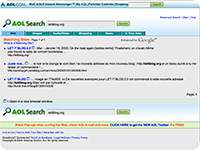 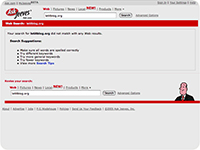 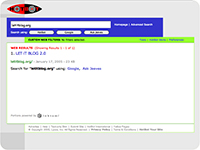 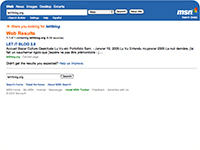 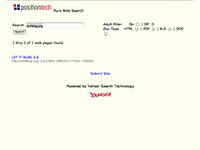  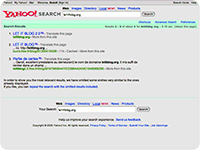 PS
: changement des 10 chansons de LET iT BLOG Radio, ambiance Noir C
Noir... PS
: changement des 10 chansons de LET iT BLOG Radio, ambiance Noir C
Noir...
|
|
| Dim. |
Lun. |
Mar. |
Mer. |
Jeu. |
Ven. |
Sam.
|
Blogoscope
Lien temporaire
Sites
Ressources
Archives
Total des entrées de ce blog:
Total des entrées dans cette catégorie :
|